Using Remote and Local Agents
Overview
Companies with large-scale enterprise networks must handle and control access from their local/private network to the external one. They must also protect and authorize access to their legacy systems, which contain sensitive data.
An OL Hub agent is a smart proxy that is responsible for creating a secured tunnel between the OL Hub to the client environment. In the client environment, a local agent (CLI) is installed, which initiates the connection to the proxy (remote agent service) and upgrades it to a WebSocket.
The remote agent service is located as a separate hub service and is deployed to the customer namespace in our OL Runtime environment and communicates between the local agent and the hub backend (SaaS). You can thereby execute calls between the Hub (SaaS) and the legacy server in the customer environment in a secure manner.
There are three main components:
- OL Hub
- Remote Agent Service - the remote agent runs in the OL Hub
- Local Agent Client - the local agent runs in the customer's container (for example, CLI or Docker image)
Note: The remote agent that is deployed in the OL Hub can be extracted to the customer’s private cloud. This enables establishing a connection between the customer's cloud and his on-prem resources without any dependence on the OL Hub.
This architecture can be summarized for the application->on-prem flow (invoke) as:
Remote Provider: Publish the invoke request to the Remote Agent Service → WebSocket → Local Agent Client
For information about using Kafka or Pub/Sub architecture, see the topic Using Kafka or Pub/Sub Architecture.
How to Install the Remote Agent Service
- In the OL Hub, in the upper right-hand side of the page click on your user and then select Agents:
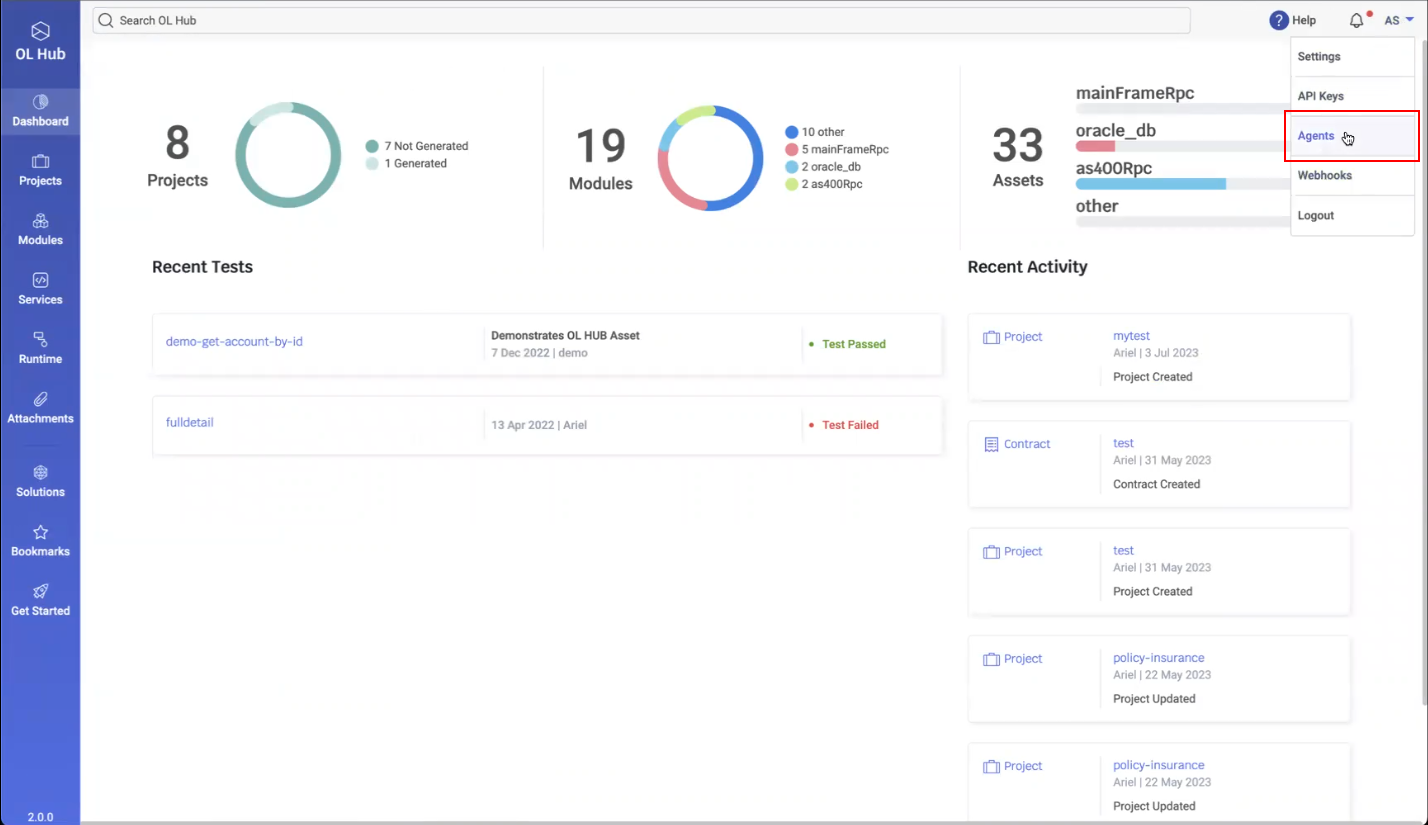
- The Settings page displays the Agents:
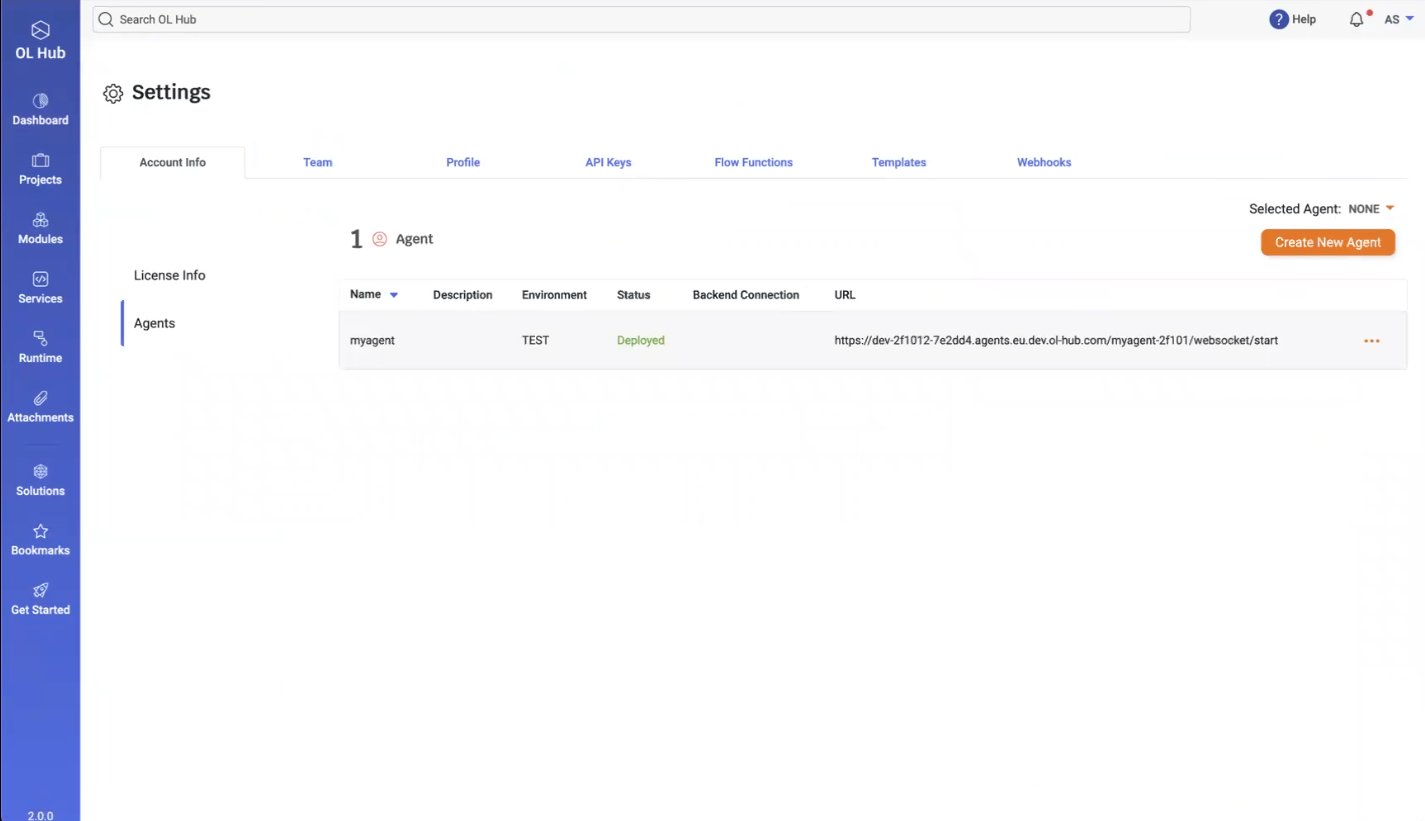
- In the above example, an agent named “myagent” exists in the TEST environment and is deployed to the listed URL. To create a new agent, click on the Create New Agent button. The Create New Agent window opens:
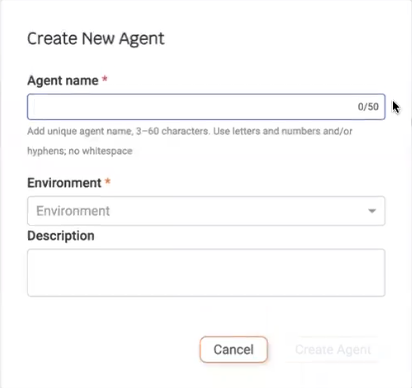
- Type an Agent name and select an Environment for the agent. Currently, there are two possible environments: TEST and PROD. Optionally, type a description of the agent.
- Click on Create Agent. The new agent is displayed:
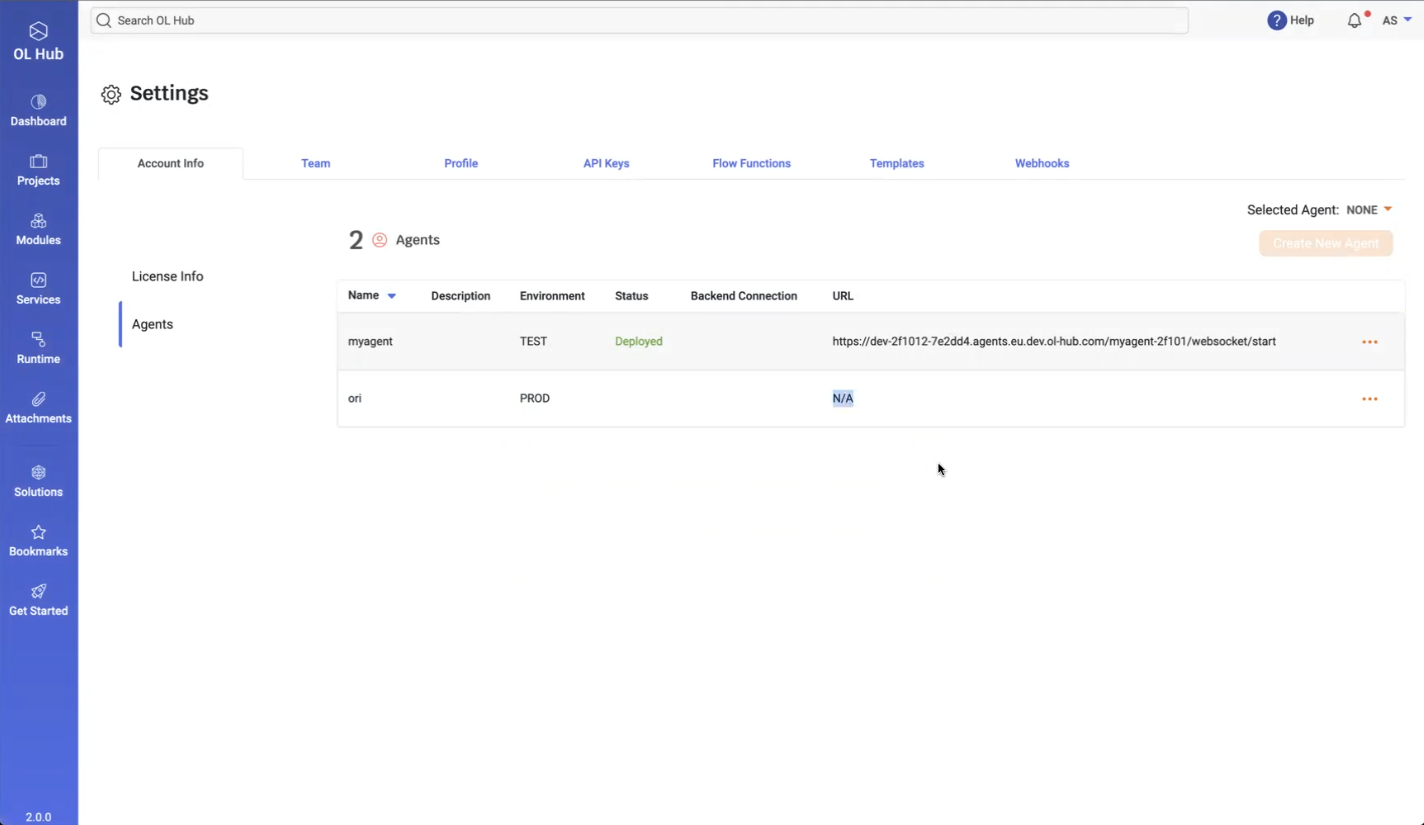
- To deploy the new agent, click on the
 icon in the agent’s row and select Deploy:
icon in the agent’s row and select Deploy:
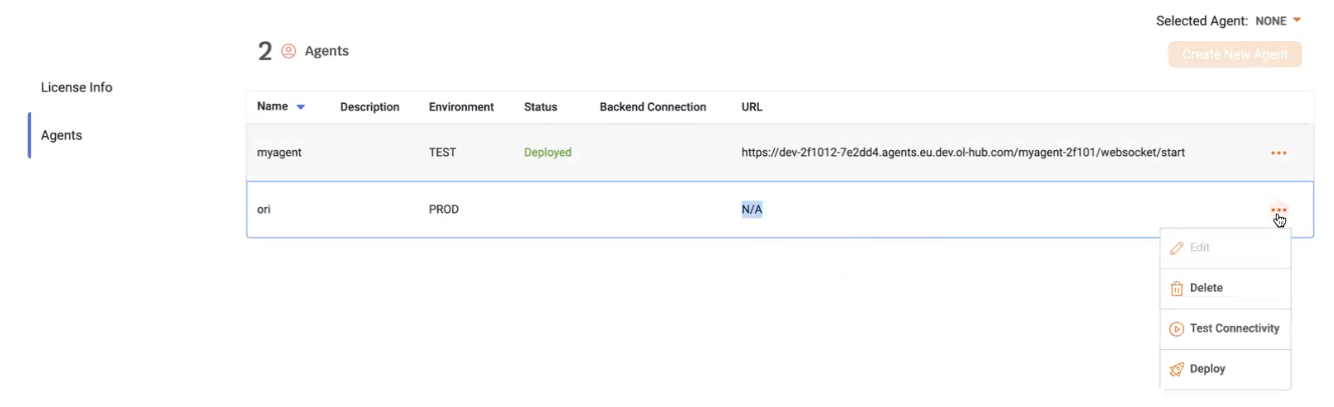
- The agent Status displays Deploying…, indicating that the deployment is in progress:
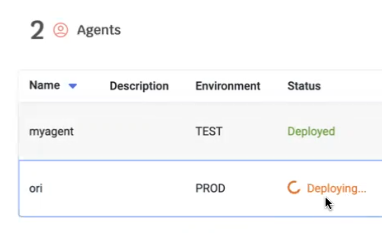
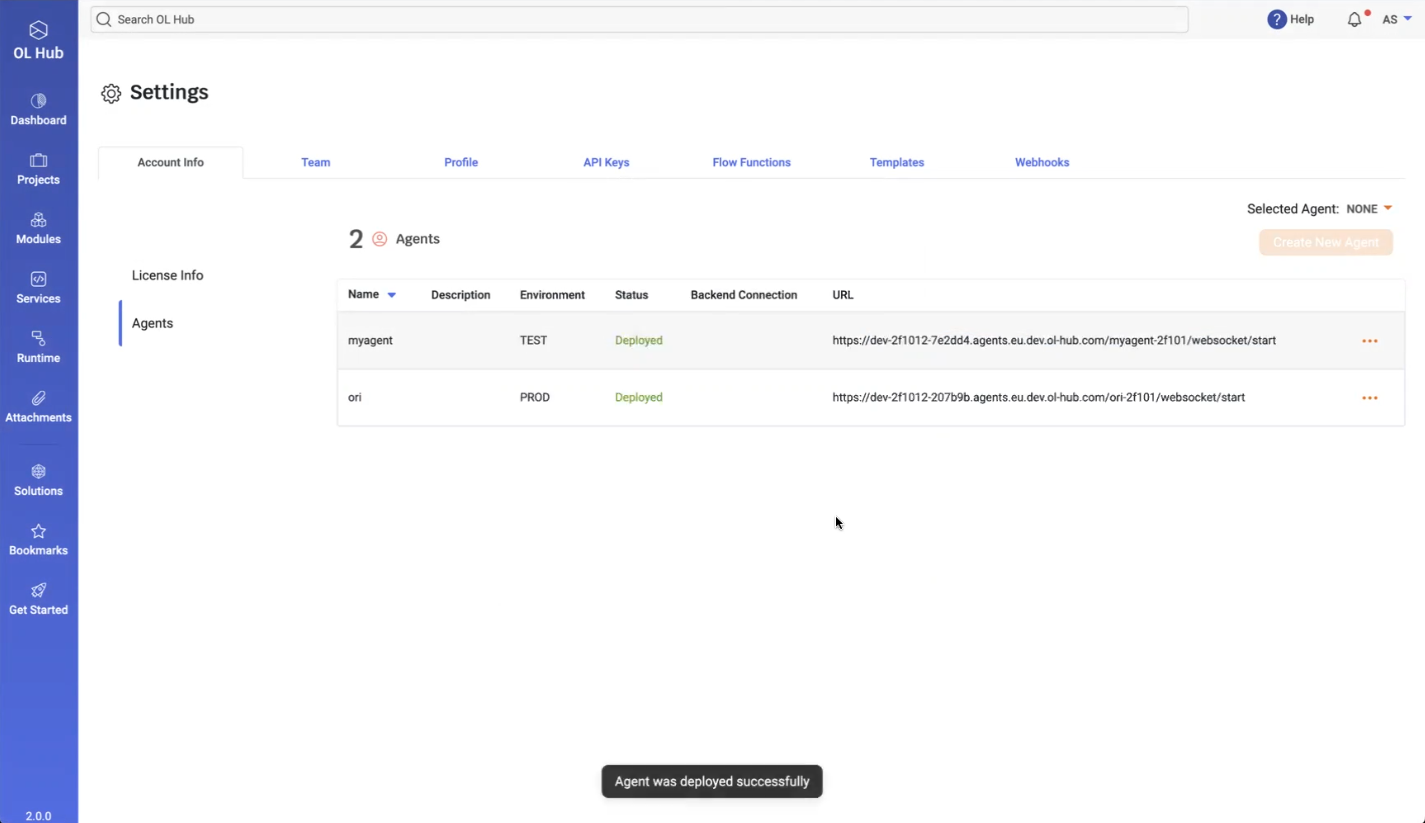
- After deployment completes, the message Agent was deployed successfully is displayed. The Status changes to Deployed and a URL is displayed:
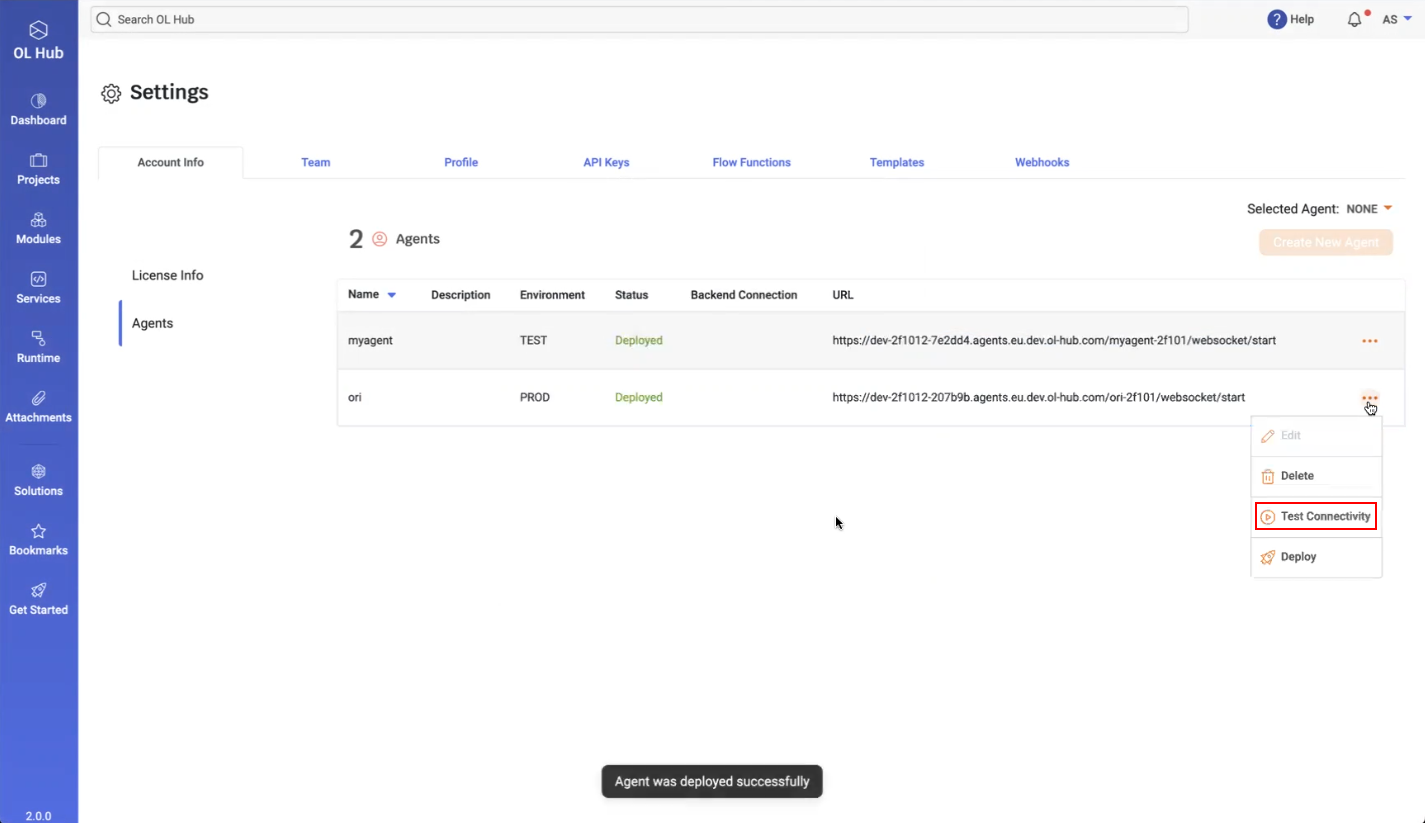
- To test the connection, click on the icon in the agent’s row and select Test Connectivity:
- You must select which agent will be active by clicking on the
 icon adjacent to Selected Agent. Initially, this is set to NONE.
icon adjacent to Selected Agent. Initially, this is set to NONE.
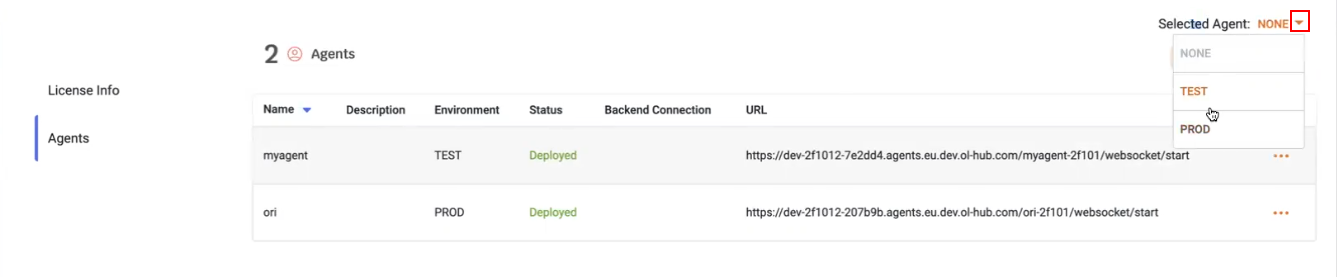
- After selecting PROD, the Agents page displays:
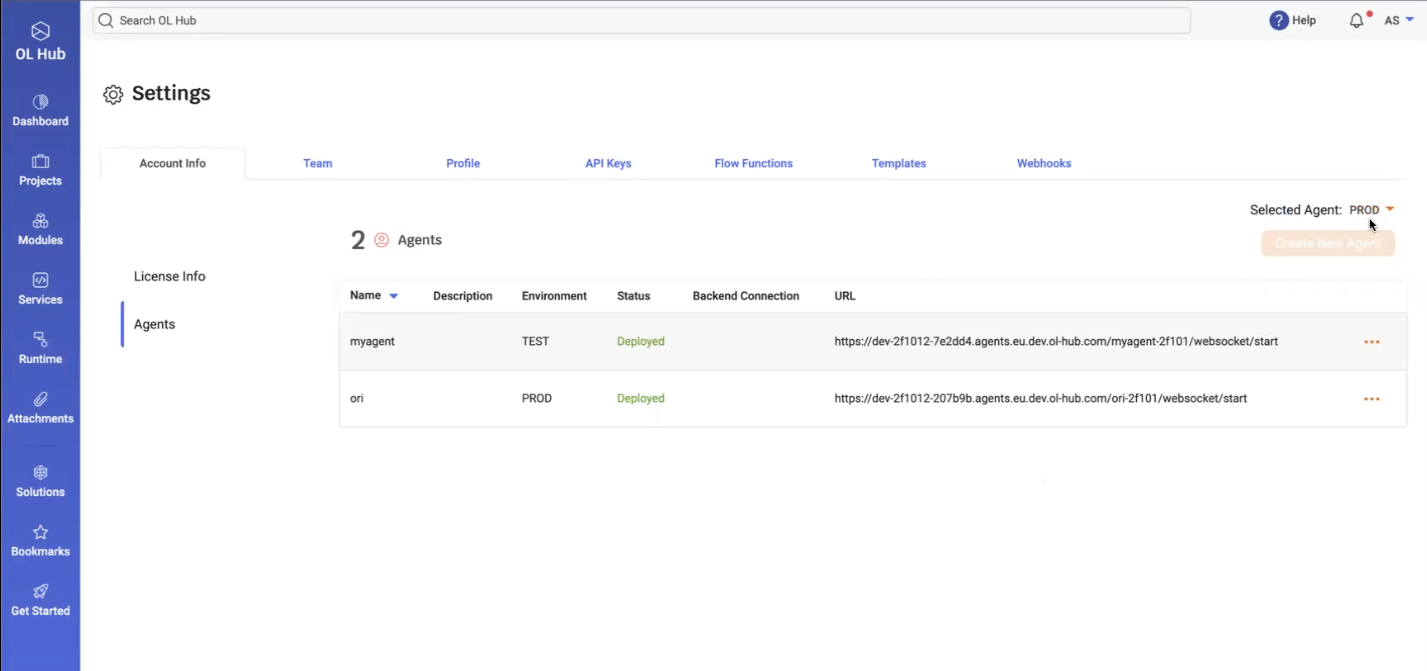
This indicates that the agent deployed in the PROD environment is now active. Communication with this OL Hub Agent requires the customer to have an agent running in his local environment.
How to Install the Local Agent
- Once the remote agent is enabled, the customer must start a local agent that will communicate with the remote agent. In the CLI, run the command ol start agent:

Note that in this example, the ol start agent command is invoked without any parameters; this assumes that a remote agent is already enabled in the OL Hub Agents Settings. You may communicate with a different deployed remote agent by invoking the command and specifying the url of a different deployed remote agent. See ol start agent or more information.
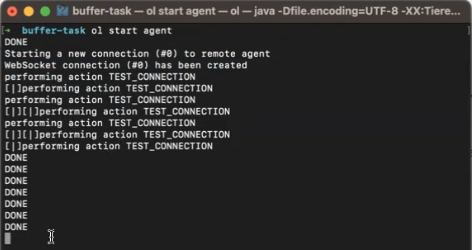
- The local agent creates a new connection to the remote agent, and the remote agent responds by creating a WebSocket connection:

- The remote agent automatically performs a test connection, and may perform several retries if not successful, as illustrated below:
- To verify that the connection was successfully created, perform the Test Connection in the OL Hub UI:
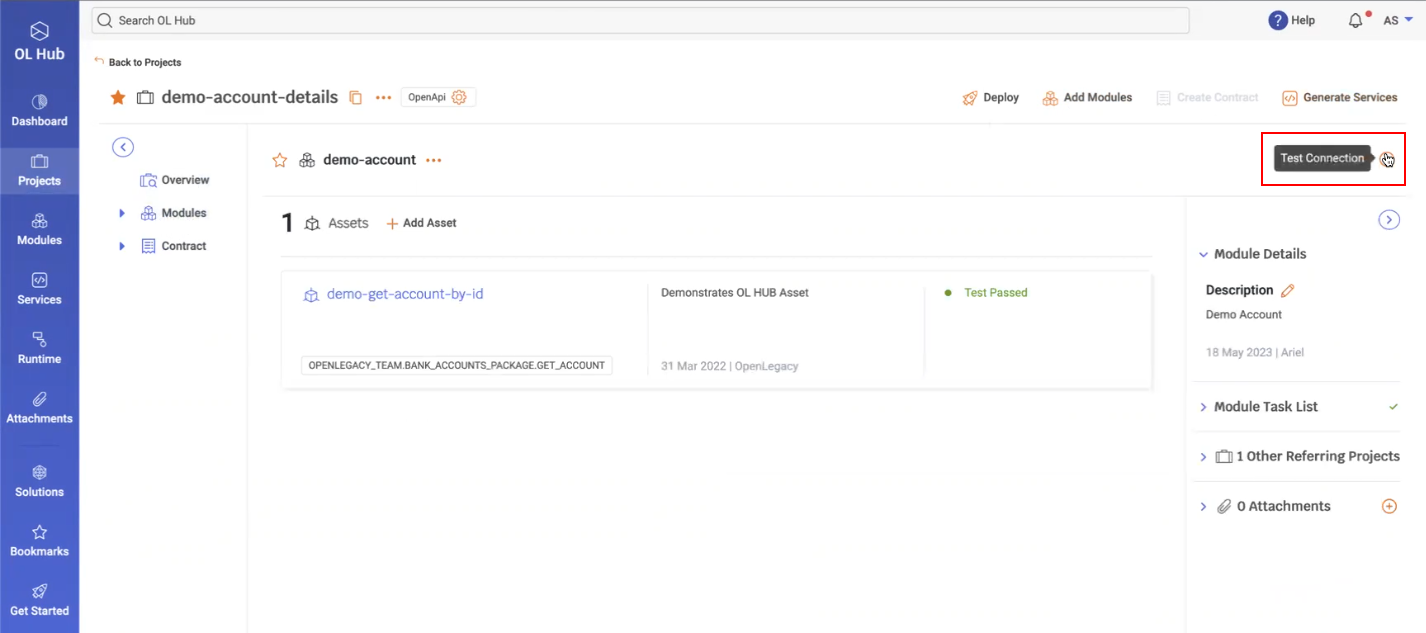
- If the Test Connection was successful, the date and time the connection was established is displayed with a checkmark (/):
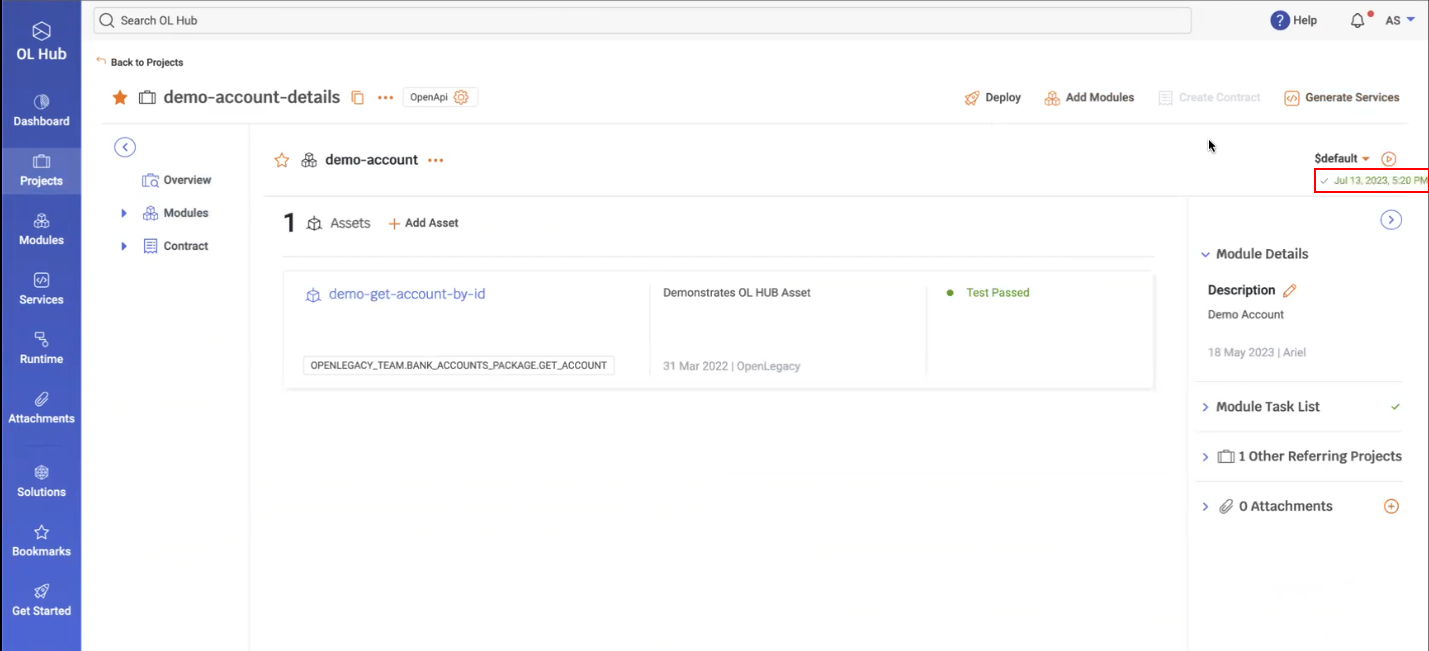
- At the same time, the CLI also displays the TEST_CONNECTION DONE message:
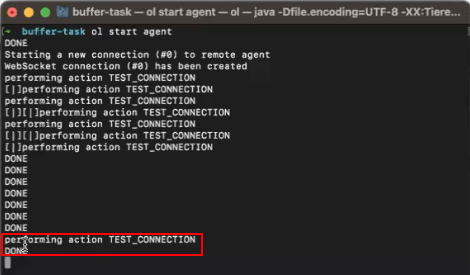
Once the WebSocket is successfully established between the remote agent and the local agent, the customer may perform all OL Hub operations using the local agent.
Using Kafka or Pub Sub Architecture
It is possible to use the local Agent Client in another architecture that uses Kafka or Pub/Sub. This enables users to leverage the agent flow to establish connections between their private cloud and on-premises environments. In this mode, each application publishes invoke requests to a specific queue or topic and receives the responses from another queue or topic. Similarly, the on-prem agents will follow the same approach. The communication between environments is facilitated by the underlying pub-sub infrastructure, ensuring reliable message exchange.
This architecture can be summarized for the application->on-prem flow (invoke) as:
Kafka Provider: Publish the invoke request to a specific Kafka topic → Local Agent Client → consume the response on another topic
Application Configuration
To configure the agent for application-level operations, the agent configurations can be defined within the flow level. This includes enabling or disabling the agent, specifying the runtime service URL, the runtime API key, and the invoke provider type (Hub, Kafka, or Remote). For Kafka providers, additional configurations such as bootstrap servers, security protocols, and consumer and producer settings can be defined.
agent:
enabled: <true/false>
url: <runtime service url>
runtime-api-key: <runtime api key>
invoke-provider-type: <HUB/KAFKA/REMOTE>
kafka: // Relevent for kafka provider
bootstrap-servers: <bootstrap servers>
security-protocol: <security-protocol>
consumer:
topic: <topic to consume from>
pool-timeout: <timeout interval for polling messages>
additional-properties: {} // every other kafka consumer configurations
producer:
topic: <topic to produce for>
ack: <ack strategy>
additional-properties:{} // every other kafka producer configurations
pool: // optional
max-size: <pool max size>
take-timeout: <retrive from pool timeout>For example:
agent:
enabled: true
url: "abc"
runtime-api-key: "aaa"
invoke-provider-type: "kafka"
kafka:
bootstrap-servers: "kafka-sandbox.openlegacy.com:9092"
security-protocol: "PLAINTEXT"
consumer:
topic: "test-kafka-json"
pool-timeout: 60000
additional-properties: {
auto.offset.reset: "earliest",
enable.auto.commit: "true",
}
producer:
topic: "TestBla"
ack: "1"
additional-properties: {
compression.type: "gzip",
}
pool:
max-size: 15Invoke Over Kafka Provider
Having multiple producers and consumers on the same Kafka topic is a common and accepted practice in Kafka architecture and can help in creating efficient and scalable data processing systems.
To ensure that the application consumer will know how to consume the messages directed to that application, message partitioning, consumer groups and correlation id can be used.
The authentication configurations depend on the Kafka cluster configurations. Either way, it can be configured as part of the Kafka producer/consumer configuration.
The consumers use a poll-based model to retrieve messages from the broker.
When utilizing the Kafka provider for the application->on-prem flow, it is important to consider the following aspects:
- Kafka Message Partitioning
Partitioning takes the single topic log and beaks it into multiple logs, each of which can exist on a separate node in the Kafka cluster. This way, storing messages, writing new messages, and processing existing messages can be split among many nodes in the cluster.
In order for multiple applications to get the correlated response, every application consumer will be assigned to all partitions. Thus, every consumer will get a copy of the message produced by the Agent Client. - Kafka Consumer Groups
Consumer groups play a key role in the effectiveness and scalability of Kafka consumers. To define a consumer group, we just need to set the group.id in the consumer config. Then, when the consumer group subscribes to one or more topics, their partitions will be evenly distributed between the instances in the group. This allows for parallel processing of the data in those topics. For a given consumer group, consumers can process more than one partition, but a partition can only be processed by one consumer. - Correlation Id
In order to correlate between request and response messages, we can make use of a unique identifier that is associated with each request message. This identifier can be included as a header/payload in the message itself and then passed along with the message as it is processed by various applications.
When a producer application sends a request message to the Kafka topic, it can include a unique identifier, as noted above. The producer application can then wait for the response message that corresponds to this request message and use the same unique identifier to correlate between the two messages.
By using a unique identifier to correlate between request and response messages, we ensure that each application is processing the correct messages and that responses are being sent back to the correct producer.
The correlationId will be generated by the application and will be part of the request payload. The Agent Client will add the correlation id to the response.
Note: On first invocation, we assign the application consumer to all partitions and end offsets.
- Kafka Agent Provider Pool
By maintaining a pool of reusable Kafka providers, we avoid the overhead of creating and closing consumer/producer instances for each message or request.
Overall, a Kafka provider pool helps optimize the usage of Kafka resources, improves application performance, and enables efficient handling of Kafka message consumption. By reusing providers from the pool, we can reduce overhead, balance the load and achieve better resource utilization, leading to improved scalability and responsiveness of Kafka consumer applications.
When using a Kafka providers pool, each Kafka consumer retains its group ID, enabling it to resume consuming from the last committed offset when it becomes available again. This ensures that messages are not missed or processed multiple times, even if a consumer leaves and rejoins the pool.
Invoke over Agent with Kafka Provider Architecture
The architecture of the Kafka provider for the application->on-prem flow is illustrated below:

Updated about 1 year ago